
Table of Contents:-
Inferior quality of data can lead to underwhelming results for your organization. It is important to identify whether the data available is actually accurate and trustworthy. In this article, we will cover some essential points you can use to enhance your data quality, irrespective of where your business lies in terms of data quality and security.
Today, businesses use more data across multiple platforms due to the digital evolution. Businesses can use native APIs and SDKs as an evolutionary method to collect, store and transfer data between different systems.
Over a period of time, as all these tools collect more data and store them based on their schema requirements, anomalies can be seen in the business. Hence, the data quality can suffer significantly and negatively impact your business. For instance, irrelevant data can turn a “custom” campaign into a general campaign. Moreover, data inaccuracy can lead to a lack of user journey among other things.
A business team that depends completely on the collection and secure storage of data can lead to better business decisions reducing the risk of data theft. More often than not, inaccurate data leads to a negative result for your business and it is best to avoid this at all costs.
As humans manage their wellbeing by getting access to proper healthcare, businesses should periodically assess the user data health. If you are unsure, then get in touch with Conneqtion Group, India’s 1st Oracle PaaS Partners for assistance. In this blog, we will take a detailed look at how you can achieve this by checking the key metrics that can serve as a guide for the future. So, let’s explore.
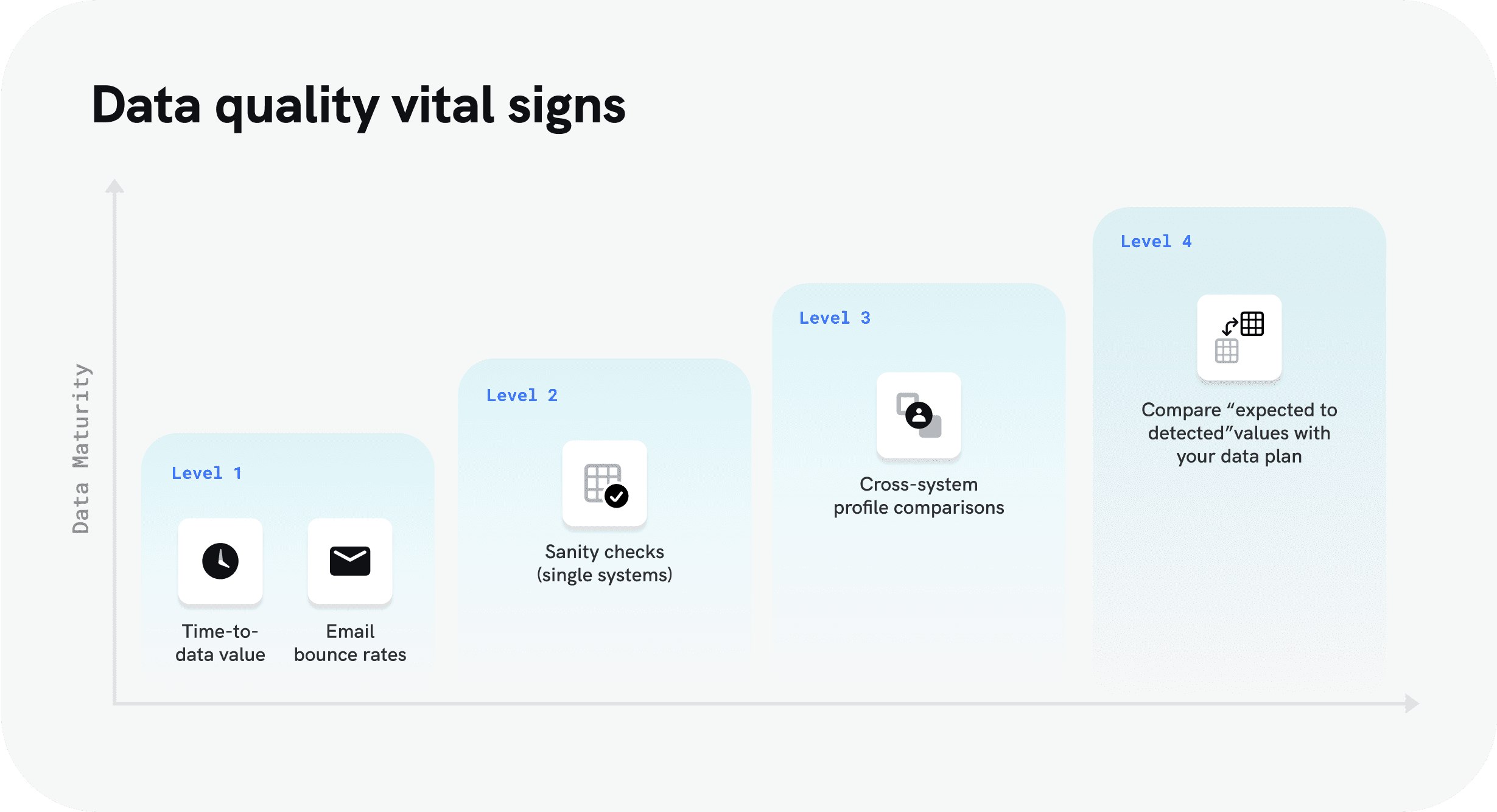
Tracking Key Data Metrics
Managing Bounce Rates
An efficient way to manage data quality is to ensure that you manage your email bounce rates properly. Each and every organization has a method of managing customer emails and service providers provide an efficient way to manage bounce rates. By managing the bounce rates efficiently, it is possible to take the control of your data health.
For instance, email service providers like Mailchimp provides a standard to manage your email lists. If the bounce rate is higher than normal, it is best to control it along with getting rid of obsolete email records. Also, it is important to check the obsolete data across all business systems to ensure that outdated records are deleted from the entire system.
Time and Efforts
The second thing is to control the time and efforts required to collect, store, transfer and use the business data wisely. It is a key step to ensure that you gain competitive advantage in a cut-throat industry.
Some of the crucial factors like data accuracy, consistency and transparency can lead to enhanced use of business data. If it is not stored properly, the IT team will need to spend more time to manage the data which can lead to human errors too.
You might also like: 11 Cloud Computing Challenges in 2022
Direct Data Quality Checks
Managing a Uniform System
A good way to ensure data quality is to run a timely sanity check in the organization. A sanity check includes a random check of data records collected and stored on the system along with periodic evaluation if needed. If there are inconsistencies or anomalies related to the data, it can lead to poor data quality which must be avoided at all costs. Managing a uniform system for data health is a must for all businesses to improve their productivity and ROI.
Data Set Comparison
In the above points, we have discussed the most potential data issues in an organization. Managing business data health is similar to managing the wellbeing of a human being. Moreover, a data set comparison is required periodically to analyze the quality of data that is stored and used across the system. This will lead to an enhancement in data consistency and overall data health.
Data Management Across Systems
Organizations that manage and use large quantities of data, multiple teams rely on individual systems for accurate data. Now, to efficiently manage the quality of data across multiple systems, it is critical to perform query tests across different systems in the organization. For instance, look for two different systems where the same data is collected and used for different purposes. By having a decently robust and seamless resolution practice across the system, you can ensure that business data is uniform across multiple systems.
A Standard Data Plan
For businesses that develop and create different data plans, there is a process to manage the data using a custom analysis. Rather than checking the same data of individual users across different systems, it might be a better option to use a uniform data model to view and use the same data across different systems. Your team can decide the guidelines and all data can be checked and analyzed based on these guidelines for accuracy and security of data.
Conclusion: Prevention is better than cure
The above key metrics to evaluate data quality in the blog above can lift your business and allow you to use data efficiently. Again, the above methods have been in practice since a long time and have been tried and tested by thousands of organizations around the world for maintaining optimum data quality. We hope that this blog has helped you understand the importance of quality data and how to protect your data in a sustainable manner. If you have any questions or concerns, please feel free to comment below or get in touch with us at [email protected].

Karan works as the Delivery Head at Conneqtion Group, a Oracle iPaaS and Process Automation company. He has an extensive experience with various Banking and financial services, FMCG, Supply chain management & public sector clients. He has also led/been part of teams in multitude of consulting engagements. He was part of Evosys and Oracle’s consulting team previously and worked for clients in NA, EMEA & APAC region.
